Data Portability and Privacy
Earlier this week, I spoke at a Justice Department / Stanford conference about antitrust issues in the tech sector. Our panel included Patricia Nakache from Trinity Ventures, Ben Thompson from Stratechery and Mark Lemley from Stanford. If you are interested you can watch the whole thing here:
📺Catch the full replay of @Stanford & @TheJusticeDept's public workshop where academics, regulators, media and investors examined the complex intersection of VC and #antitrust. @pnakache's panel w/ @benthompson @nickgrossman @marklemley starts at 5:55:00. https://t.co/XdNqfdNcLU pic.twitter.com/PIcctzY7Hv
— Trinity Ventures (@trinityventures) February 13, 2020
The main point I tried to make was that cultivating the development of blockchain and cryptonetworks is actually a critical strategy here. Regular readers will know that I don’t shut up about this, and I held to that on the panel. This point is painfully absent in most conversations about market power, competition and antitrust in the tech sector, and I will always try and insert that into the conversation.
To me, blockchains & crypto are the best “offense” when it comes to competition in the tech sector. Historically, breakthroughs in tech competition have included an offense component in addition to a defense component (note that the below only focuses on computing, not on telecom):
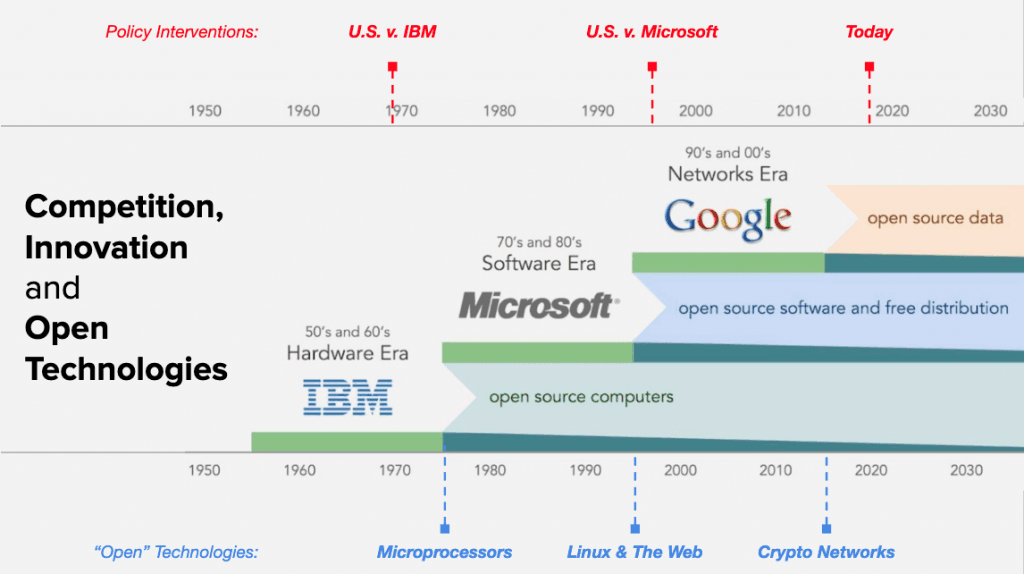
Credit: Placeholder / USV
The “defense” side has typically included a break up (US vs. AT&T) or some kind of forced openness. Examples of forced openness include the Hush-a-phone and Carterfone decisions which forced openness upon AT&T. Several decades later were the (ongoing) battles over Net Neutrality with the ISPs. The discussion about data portability and interoperability brings the same questions to the applications / data layer.
Data portability & interoperability are important for two reasons: 1/ because they focus on a major source of market power in the tech sector, which is control of data (“break up the data, not the companies”), and 2/ because they represent a category of regulatory interventions that are just as easy for small companies to implement as large ones, unlike heavy approaches like GDPR that are easy for big companies to implement but hard on startups.
That said, when you dig into the issue of data portability, there are some hard problems to solve. I don’t believe they are insurmountable, but I also believe they haven’t been resolved as of yet.
For context, data portability is the idea that a user of a tech service (e.g., Google, Facebook, Twitter, etc) should be able to easily take their data with them and move it to a competing service, if they so choose. This is similar to how you can port your phone number from one carrier to another, or how in the UK you can port your banking data from one institution to another. Both of these examples required legislative intervention, with an eye towards increasing competition. Also, most privacy regimes (e.g., GDPR in Europe and CCPA in California) have some language around data portability.
Where it gets more complicated is when you start considering what data should be portable, and whose data.
For example, within tech companies there are generally three kinds of data: 1/ user-submitted data (e.g., photos, messages that you post), 2/ observed data (e.g., search history or location history), and 3/ inferred data (inferences that the platform makes about you based on #1 and #2 — e.g., Nick likes ice skating). Generally speaking, I believe that most type #1 and type #2 data should be portable, but most type #3 probably should not.
To add to the complication is the question of when “your” data also includes data from other people — for example, messages someone else sent me, photos where I was tagged, contact lists, etc. This was at the heart of the Cambridge Analytica scandal, where individual users exporting their own data to a third-party app actually exposed the data of many more people, unwittingly.
I’d like to focus here on the second category of complications — how to deal with data from other people, and privacy more generally, when thinking about portability. This is a real issue that deserves a real solution.
I don’t have a full answer, but I have a few ideas, which are the following:
First, expectations matter. When you send me an email, you are trusting me (the recipient) to protect that email, and not publish it, or upload it to another app that does sketchy things with it. You don’t really care (or even know) whether I read my email in Gmail or in Apple Mail, and you don’t generally think about those companies’ impact on your privacy expectations. Whereas, when you publish into a social web platform, you are trusting both the end recipient of your content, as well as the platform itself. As an example, if you send me messages on Snapchat, you expect that they will be private to me and will disappear after a certain amount of time. So if I “ported” those messages to some other app, where, say, they were all public and permanent, it would feel like a violation – both by me the recipient and by Snap the platform. Interoperability / portability would change that expectation, since the social platform would no longer have end-to-end control (more like email). User expectations would need to be reset, and new norms established. This would take work, and time.
Second, porting the “privacy context”: Given platform expectations described above, users have a sense of what privacy context they are publishing into. A tweet, a message to a private group, a direct message, a snap message, all have different privacy contexts, managed by the platform. Could this context be “ported” too? I could imagine a “privacy manifest” that ships alongside any ported data, like this:
# privacy.json
{
"content": "e9db5cf8349b1166e96a742e198a0dd1", // hash of content
"author": "c6947e2f6fbffadce924f7edfc1b112d", // hash of author
"viewers": ["07dadd323e2bec8ee7b9bce9c8f7d732"], // hashes of recipients
"TTL": "10" // expiry time for content
}
In this model, we could have a flexible set of privacy rules that could even conceivably include specific users who could and could not see certain data, and for how long. This would likely require the development of some sort of federated or shared identity standards for recognizing users across platforms & networks. Note: this is a bit how selective disclosure works with “viewing keys” in Zcash. TrustLayers also works like this.
Third, liability transfer: Assuming the two above concepts, we would likely want a liability regime where the sending/porting company is released from liability and the receiving company/app assumes liability (all, of course, based on an initial authorization from a user). This seems particularly important, and is related to the idea of expectations and norms. If data is passed from Company A to Company B at the direction of User C, Company A is only going to feel comfortable with the transfer if they know they won’t be held liable for the actions of Company B. And this is only possible if Company B is held accountable for respecting the privacy context as expressed through the privacy manifest. This is somewhat similar to the concept of “data controller” and “data processor” in GDPR, but recognizing that a “handoff” at the direction of the user breaks the liability linkage.
Those are some thoughts! Difficult stuff, but I think it will be solvable ultimately. If you want more, check out Cory Doctorow’s in-depth look at this topic.